
Seeing like a machine: finding the edge of Space Invader
👀 What's happening inside a digital mind when it's looking at pictures?

My favorite thing about Google Photos has been its search feature. Looking for a photo of that hike in Iceland? Type “hike” and the right photos show up
There are no tags on the photos, I never labelled them as “hiking”. How would a computer even know what hiking is?
We already saw how neural networks can learn insights from tabular data (Titanic survival predictions, Movie recommendations). But what about visual data? Neural network is just an organized way of multiplying numbers together, how could it ever “see” anything?
Seeing like a computer
Computers represent pictures as arrays of numbers.

This picture of a Space Invader mosaic in Paris (PA_1249), is just an array of numbers. If we simplify the image a little to disregard color, reduce the resolution and zoom in, to the computer it would look something like this:

Each number represents the brightness of the corresponding pixel. While we humans “see” the pixel brightness, the computer only cares about the numeric values.
🎭 Mask-making
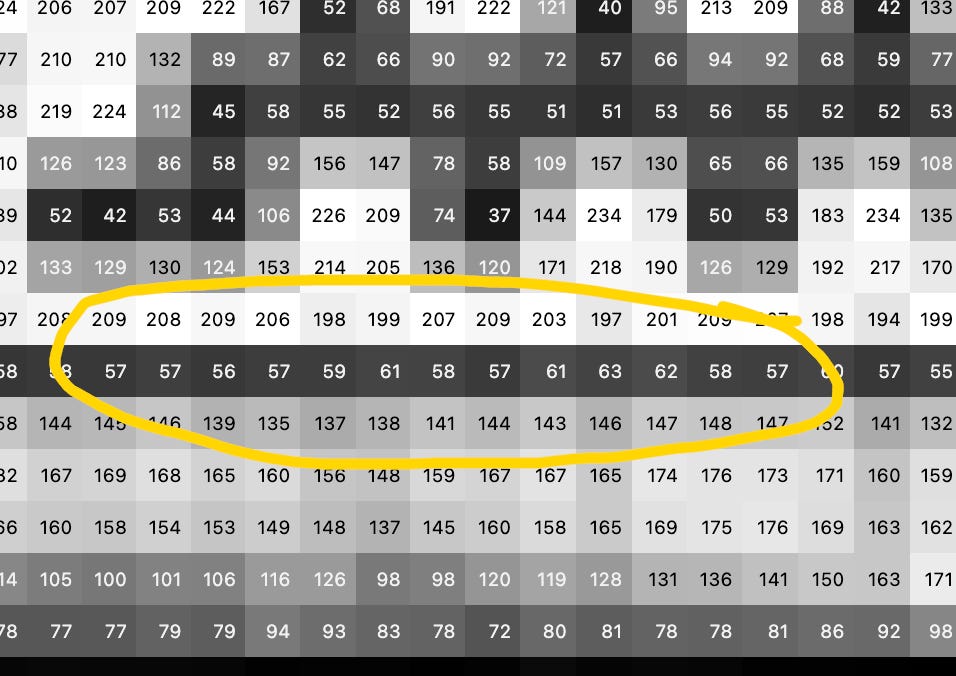
How a computer could “see” anything at all? Let’s say we want to teach the computer to find dark horizontal lines line this one on the bottom edge of the Space Invader:
We can represent the basic shape that we’re looking for as a 3x3 mask.
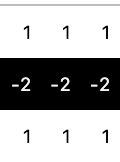
The mask represents the pattern of pixel values we’re looking for. In this case, because we want to match a horizontal dark line, we make a mask with low pixel values in the middle, surrounded by higher values above and below. (We typically want the values to add up to 0, that’s why we’re using -2s in the middle row and +1s above and below.)
Let’s now use this mask to find the edge of the Space Invader!
Finding the edge
Once we have our mask, we can start moving it over the entire picture, pixel by pixel. In each place we simply multiply the values of the surrounding pixels by the corresponding values in the mask.
So for example, in this place:

… we’d multiply together (198 x 1) + (199 x 1) + (207 x 1) + (59 x -2) + (61 x -2) + (58 x -2) + (137 x 1) + (138 x 1) + (141 x 1) = 664
Once we do this for every pixel in the picture, we have the results of our “pattern recognition". It’s a new picture, where the brightness of each pixel represents how well the pattern we’re looking for matches the content of the original picture in the given place.
The resulting picture looks like this:

We’ve got it! All of the pixels representing the edge we are looking for have high values (over 500), all other pixels have lower values. The computer “found” the pattern.
We can use the same method to find any other small pattern that we can express using a 3x3 mask. This technique is called “convolution”, and it’s the basic building block of most modern image recognition systems.
The rest of the owl
But how to go from detecting simple 3x3 patterns to finding anything in the picture, including abstract concepts like “hiking” ?

The answer is fascinating, and involves using layers upon layers of convolutions with masks that are learned from data, instead of being hand-written.
Let’s come back to this in a future edition 💫.
In other news
💀 “I’m glad I’m dead!” Someone made an AI-generated stand-up comedy special in the style and voice of the great, currently deceased, comedian George Carlin. It’s pretty good until you go back to watch the real thing. Meanwhile, the family lawyers are suing the authors of the AI-generated video.
🎨 Can you tell apart deep fakes from real photos? Try the Axios quiz on the occasion of the upcoming US election season.
🎤 State of generative AI in Davos, upbeat panel with some of the greatest researchers in the field.
Postcard from Bourg-Saint-Maurice
One more memory of the mountains last week. Meanwhile the weather in Paris is becoming warm and almost nice, looking forward to the spring on the horizon 💫.
Have a nice week,
– Przemek