
Learning from disaster: what happened to James Kelly
🚢 The baseline is everyone dies; dipping my toes in data science competitions

It’s 11 April 1912, your name is James Kelly. It’s a rare sunny day in Queenstown, Ireland. You’re about to board the Titanic. You’re uncomfortably excited about the journey to New York City.

Unfortunately, we know what happened next. Titanic sank and most of the passengers died. What about James Kelly, did he survive the disaster?
As bizarre as it sounds, at least 15 thousand people have been wondering about that…
Kaggle Titanic competition
Kaggle is the leading online platform for data science competitions. These are computer science puzzles where people practice data analysis and prediction techniques on real data sets.

The most popular entry-level competition on the site is about Titanic survival predictions. Let’s take a look at how the competition works and earn some Kaggle points 💫.
Training data, test data
We’re given two files. One contains information about 891 of the Titanic passengers. For each of them we’re given their gender, age, passenger class, port of embarkation (🏴 Southampton, 🇫🇷 Cherbourg or 🇮🇪 Queenstown) and a bunch of other details that this screenshot is too small to fit. Crucially, we’re also told whether each of those passengers survived the sinking.
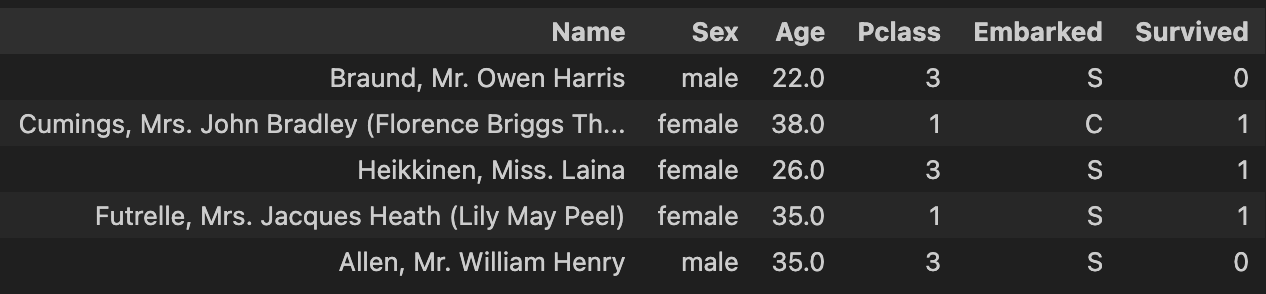
The second file has almost identical format and covers further 418 passengers. The twist is that for those, we’re not told if they survived. Indeed, predicting whether they survived the disaster is the goal of the competition! In the first line of this test file we find our protagonist, Mr. James Kelly.

Everybody dies
We’ll start with something simple. We know that most of the passengers died… so let’s submit a file that just says that everyone died.

Boom, that’s already 62% accurate! This looks very silly but it’s important: we want to have a baseline to later evaluate more complicated solutions.
Imagine how deluded we’d be if we skipped this step, built a complicated machine learning engine, got accuracy of 60% and thought it’s working pretty well. Without baseline we can’t tell if “60%”, or any other result, is good!
Decision trees
The second approach I tried is using an old-school machine learning technique called decision trees. As opposed to the baseline approach, now we’re going to actually train model on the example data and use it to make predictions on the test data set.
Using a “black box” library like sklearn we can do this in very little code:

And with that we’re up to 75% accuracy!

We have no idea what’s going on and how the model predicts the survival outcome, but it works a bit better than the baseline and it was very simple to put together. Let’s do some actual work in the last solution.
ML model by hand
In the previous solution we used a “black box” library that did all the work for us. How would it look to “do the work” ourselves?
Let’s do a bit of math. This is going to be very … elementary, but it illustrates the ideas at the heart of all the fancy neural network techniques out there. We’re going to define a simple formula that’s meant to predict the survival outcome based on passenger parameters:
The hypothesis is that maybe there are values of p_0, p_1, p_2 and p_3 that multiplied by the passenger data will produce a value close to 0.0 for passengers who don’t survive, and close to 1.0 for those that do.
How do we find good values for p_0, p_1, p_2 and p_3 ? Here’s the “secret” (not-at-all-secret) of all Deep Learning solutions:
start with random values of parameters
calculate how good the predictions are on the training set
try fiddling with the parameters a little bit, see in which direction to adjust them to improve the predictions
adjust the parameters based on what you found in 3., come back to step 2. Repeat.
Results
After 5000 iterations of this algorithm, we get parameters that seems to be doing OK.
The calculated parameters include -0.3791 for age, -0.4767 for gender, 0.3777 for whether the passenger is in the 1st class. This gives us insights into what the model learned about the data: it seems that the strongest predictor of the survival is the gender of the passenger (women more likely to survive).
Age and being in 1st class had comparable impact on the outcome. Younger people seem more likely to survive, and so are first class passengers.
The predictive accuracy of our simple formula seems OK:

Each blue dot represents the expected outcome from the training set. A blue dot at 1.0 means the passenger survived, a blue dot at 0.0 means they died.
The green/red dots represent the predictions from our formula: green for correct predictions (closer to the right outcome) and red for incorrect predictions (closer to the wrong outcome).
Was all this ML-by-hand worth it? Let’s see:

Yes! We’re up to 77% accuracy, beating the black-box decision tree solution 💫.
What happened to James Kelly?
🕯️ He died.
Postcard from Cobh

Photo from my 2016 visit to Cobh, Titanic’s last port of call. The town that used to be known as Queenstown returned to its original name in 1920.
Have a great week 💫,
– Przemek
This has got to be one of the more cynical and funny models you have expressed. It made me more insightful and made me chortle at the same time.