
Everything all at once
💥 How more compute power coupled with research breakthroughs enabled the explosion of generative AI

Why is everything happening all at once?
Text generation, image creation, voice synthesis, language models. We seem to be living a Cambrian explosion of generative AI. But why is all this happening now, everywhere and all at once?

The versatile neural network
The state-of-the-art systems in all the different domains of generative AI, whether it's image generation, text generation, audio synthesis, or creating deep fake videos, share the same underlying technological foundation: neural networks.
Seen from the outside, a neural network is a statistical learning machine. Seen from the inside, it’s a pipeline of additions and multiplications. We put those mathematical building blocks together and then “train” the network on example inputs.

This type of machine is extremely versatile. We already saw how this architecture can be used to generate Shakespearean text. With a small modification, we could use a similar same single-layer neural network to, for example, recognize handwritten digits:
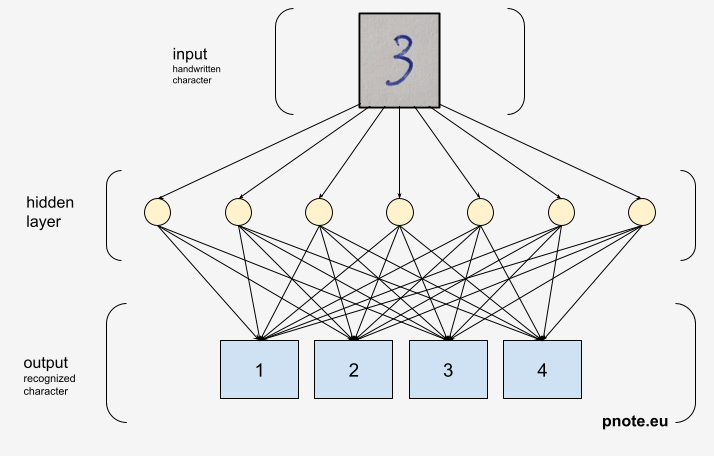
Similarly, sound synthesis uses neural networks trained on large sets of text-to-sound examples. Image generation is usually done by progressively denoising what’s initially a random picture, using a neural network trained to remove noise from images.
It’s neural networks wherever you look.
More, more, more compute power
OK, so neural networks are versatile and can be applied to various problems. But how did they suddenly become so much better?
Neural networks has been around for a long time. In 1989, young Yann LeCun (today the chief AI scientist at Meta) was already training his LeNet-1 to recognize handwritten characters:

And yet, most of the 90s and early 2000s were a period of the “neural network winter”. This changed with the landmark 2012 “AlexNet” result by Alex Krizhevsky, Ilya Sutskever and Geoffrey Hinton. The team, then at the University of Toronto, used convolutional neural networks trained using GPU accelerators to win the prestigious ImageNet image classification competition.
A modern day profile on Ilya Sutskever (one of the cofounders and recently departed ex-chief scientist of OpenAI) relays some of the legends surrounding the use of GPUs in AlexNet:
Huang says that Nvidia sent the Toronto team a couple of GPUs to try when they were working on AlexNet. But they wanted the newest version, a chip called the GTX 580 that was fast selling out in stores. According to Huang, Sutskever drove across the border from Toronto to New York (…) and apparently filled a trunk with them.
Hardware acceleration and large scale compute power were missing ingredients needed to unlock the potential of neural networks.
Research breakthroughs
One more missing ingredient was simply more progress needed in the science of designing and training neural networks.
The last 10 years brought a parade of improvements big and small, for example:
💡 Kaiming initialization (2015), helping to pick the right initial values for training a neural network
🔬 Batch normalization (2015), a way of preserving numerical stability while training neural networks
🤖 The transformer architecture (2017), underlying all the large language models of today and increasingly adopted for other (non-text) modalities
Those advancements did not just benefit one specific application of neural networks. They are foundational, improving the state-of-the-art for various application domains.

This creates the adoption/innovation flywheel: as neural networks improve, they are adopted in more domains, driving even more interest in improving them further.
Conclusion
The acceleration of progress in generative AI over the last few years is fuelled by three driving factors:
🚀 The shared foundation of deep neural networks. All the various domains of AI are using the same theoretical and often practical stack, so benefits driven by one domain benefit others.
⚙️ More compute power: the early pioneers of neural networks like Yann LeCun were right all along: the neural networks are versatile and can be very powerful. But they needed significantly more training compute power to demonstrate their full potential.
🔬 Research breakthroughs: a number of architectural innovations allowed creating systems that learn complex tasks better (e.g. transformers) and made it easier to train the network (e.g. batch normalization).
Credits
Thank you to Alexander who posted the question that inspired this post 💫.

In other news
📰 Ben Evans on Apple Intelligence: Apple has showed a bunch of cool ideas for generative AI, but much more, it is pointing to most of the big questions and proposing a different answer - that LLMs are commodity infrastructure, not platforms or products.
🤖 Google DeepMind released Gemma 2 , the latest iteration of Google’s open weight models. The 27B Gemma 2 model is designed to run inference efficiently at full precision on a single Google Cloud TPU host, NVIDIA A100 80GB Tensor Core GPU, or NVIDIA H100 Tensor Core GPU, significantly reducing costs while maintaining high performance. This allows for more accessible and budget-friendly AI deployments.
💯 Hard to make, easy to check. AI tools may be most helpful for problems where it's hard to come up with the right solution, but given a solution it's easy to check it. (Brainstorming is one example: I'm happy to ask Gemini for 10 ideas for a catchy title for my post draft, because it takes little effort to discard the bad ones and sometimes it spits out a nugget I keep.)
Postcard from Paris

Last week I had the pleasure of debuting in French amateur theater. We played Thieves' Carnival, a play we’ve been preparing since October. Thank you to the entire troupe and our most amazing teacher 🫶.
We played a week ago and I’m still calming down :).
Have a great week,
– Przemek
Awww, I have an impression that you'd be pretty good in a role of the Little Prince 😅