


Lost in tokenization: Tokyo in context windows
🇯🇵 Breakfast beans surprise; Context windows and why we want them big; Tokyo in the evening sun

What is this and how do I eat it?

Large Language Models can be of great help when travelling. They can answer very specific questions, such as “What is this thing and how do I eat it?” (Real problem.)
In this case GPT-4 got it right:

If we keep the conversation going, the model will use the conversation context to understand follow-up queries. For example, we can ask if we can bring some back to Paris, and there’s no need to specify that we mean the beans:
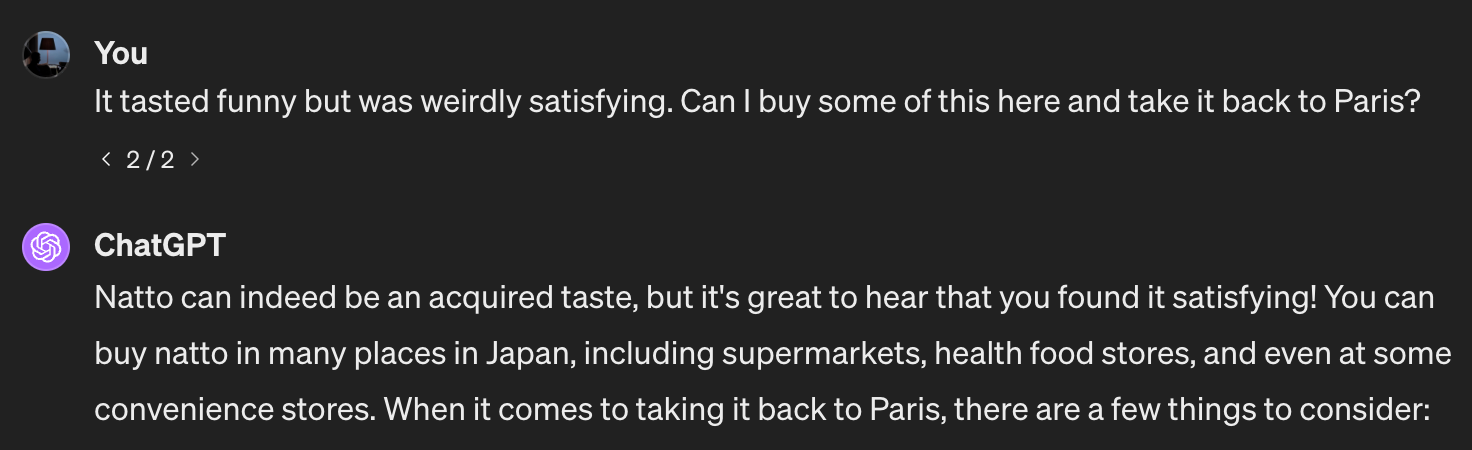
How does the conversation context work?
Tokens
Large Language Models are “completion engines”: they take some text as input, and keep predicting what comes after, one chunk at the time.
The chunks are called tokens. A single word is usually represented as one or more tokens. For example, this is how ChatGPT tokenizes my query above:

The output from the model is also produced token-by-token:

When you see ChatGPT progressively “typing out” its response, it’s not just a visual effect. It’s the model generating the response one token at a time.
Context window
When generating the response, the input to the model is the entire conversation history until that point. It includes all the questions and all the reponses, put together as one chain of tokens. To the model it looks something like this:

Yes, even the demarcation of what is said by the user and what is said by the chatbot in previous responses is treated as regular text and tokenized.
And here comes the catch: the bigger the conversation history that we pass to the model, the more calculations it needs to perform to produce the answer. (And the more of the precious GPU memory it will use.)
For this reason, the maximum number of tokens that the model can receive as input is limited. This input capacity is called the context window size. My short conversation about natto beans (two questions and two responses) contained 350 English words, translating to ~500 tokens. Some typical context window sizes:
Gemma 2B (the new tiny open model from Google): 2 000 tokens
GPT-4: 8 000 tokens
Gemini Pro, Mistral Large: 32 000 tokens
Claude 2 (Anthropic’s model known for its large context window): 100 000 tokens
So in case of GPT-4, we could keep chatting about Japanese food for about 16 times longer (8000 / 500) before running out of the context window. This seems plenty, so why would anyone want an even longer context window?
What would you do with a really big context window? Trip planning

We only need a big context window when we want to process large amount of information at the same time. One typical use case is having a long conversation and then asking for a summary at the end.
Gemini is a pretty good chatbot to try this, as it has a large context window (32k tokens, as opposed to 8k tokens in GPT-4) and a direct export to Google Docs.
After asking ~10 questions about an upcoming trip (What places in Tokyo are best for night photography? Is it allowed to climb Mount Fuji in winter? etc.), we ask it produce a summary:

We can ask to make the summary longer if it’s too concise:

And in the end we can export it to a Google Doc with a single click 💫.

If this works well, it’s because the entire conversation fits in the context window, allowing the model to get all the details right ✅.
In other news
🤖 Gemini 1.5 (a new Gemini model from Google announced a few weeks ago) is advertised as supporting a huge 1 million token context window 😲. (Available in experimental preview.)
🎨 Meanwhile, image generation in Gemini is turned down after controversies. Benedict Evans explains the core challenge: Now suppose you want to be sure - really sure - that your image generator will never claim that only white people can be doctors, or only black people go to prison? Do you make a list of hundreds or thousands of reserved categories… or tell the site always to produce a diverse range of people in the results? That seems safe - until someone asks for pictures of Nazis.
Aside
📖 I read Murakami’s Norwegian Wood on the way to Japan. Such a beautiful story about love and being human. “If you only read the books that everyone else is reading, you can only think what everyone else is thinking” is a bit of an ironic quote, as the book is an international bestseller.
📸 Tokyo photo tours organized by a friend of this newsletter. For those who still prefer human instruction over AI advice :).
Postcard from Tokyo

Tables with a view at the Google office in Tokyo Shibuya. Starting a week of vacation now, looking forward to trying more puzzling and delicious food !
Have a great week 💫,
– Przemek
“If you only read the books that everyone else is reading, you can only think what everyone else is thinking” - on this note... are we at a bottleneck with AI? While we can feed it personal requests and guide its answers by prompting the question in one direction, does it run the risk of tunnelling our lives? Suppose we know little about Japan and ask for good first-time trip planning. Will it not give us the results based on the vast majority of answers already out there, further pushing travellers as a collective whole in the same singular direction?
For more exciting food to try, I suggest Okonomiyaki. Best to eat in Osaka or Kyoto!