
Squeezing more points from the Titanic dataset
🏆 What you actually spend time on in data science competitions

Sometimes it’s good to be lazy.
Last week we saw how to set up a simple neural network to solve the Titanic survival prediction problem on Kaggle.

We didn’t do anything special beyond picking the right library and feeding the passenger data to it. With this, we got a pretty good solution reaching the top 20% of the scoreboard. Fastai took care of a lot of the details that are not so interesting but easy to get wrong. (Designing the neural network, normalizing the variables, ensuring numerical stability, etc.)

But it was somewhat unsatisfactory to have the library do all of the work. So today let’s get down to it and find a way of beating the top score from last week!
Rig the dice
First, let’s rig the dice so that the scores are reproducible. Every time our solution runs on Kaggle, there’s an element of randomness that makes the results unpredictable within some small margin. Let’s fix this:
random.seed(42)
np.random.seed(42)
torch.manual_seed(42)and submit again:

Oh, this made our score … slightly worse. It turns out we got a lucky dice roll when we submitted before 🙈. Bad luck this time, but we’ll stick with it. Let’s see what we can do to recover.
It’s in the title
Last week we discarded the passenger names from the data set. Almost all of them are unique, so there’s no way they could be used for predictions in any meaningful way… right?
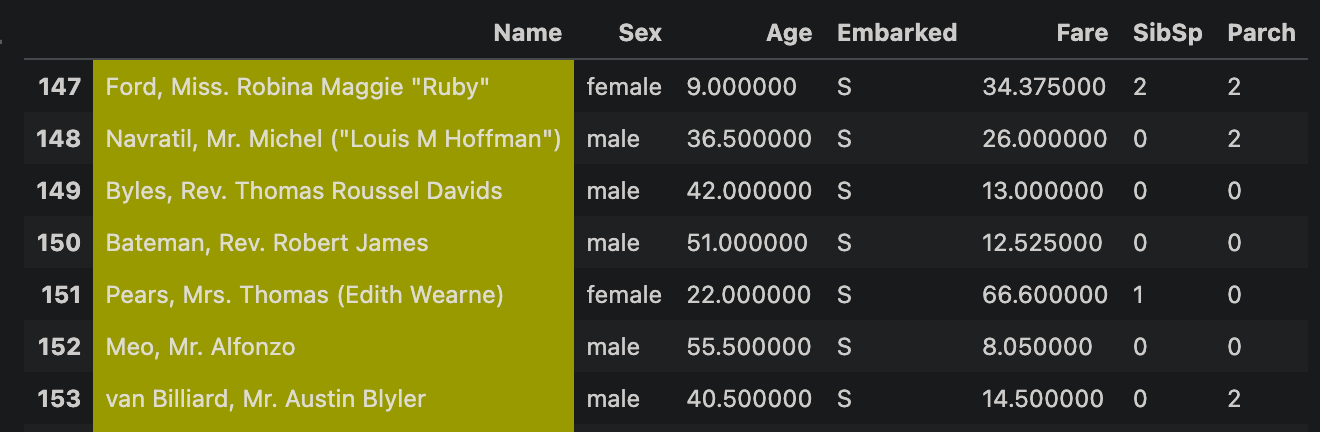
Wait, those names include titles!
The distinction of “Mrs” vs “Miss” indicates marital status, which could influence survival probabilities. And there’s more: some passengers have titles indicating education (“Dr”), religious role (“Rev”), nobility status (“the Countess”) and military titles (“Major”, “Col”). This sounds like a legit categorical variable the model could take into account.

Let’s then add a step that extracts titles from names and feed the titles to the model:

Once we add “Title” as a feature and retrain the neural net, we’re half percent better!

Less is more
Sometimes more features isn’t necessarily better. Any variables that aren’t relevant to the survival probabilities will just add more noise to the training, making it harder for the neural network to figure out what actually matters.
In the Titanic data set there are two mysterious continuous features:
SibSp is the number of passenger’s siblings and spouses present onboard
Parch is the number of passenger’s children and parents present onboard
So both numbers count the family members onboard, but each tracks different types of family relationships. I’m not convinced that grouping of siblings with spouses and children with parents is useful… What if we simplified this and replaced them with a single number tracking the total family size?

Could reducing the amount of data we give to the model improve our score?

Yes, we get our best result so far! Turns out that removing data that’s not useful from the training set can improve performance.
And with this we accomplish the quest to beat the best score from last week 💫. Note that we didn’t change anything in the neural net architecture generated by fastai. I played with it a bit, but found it hard to improve on the defaults that the library generates.
Conclusion
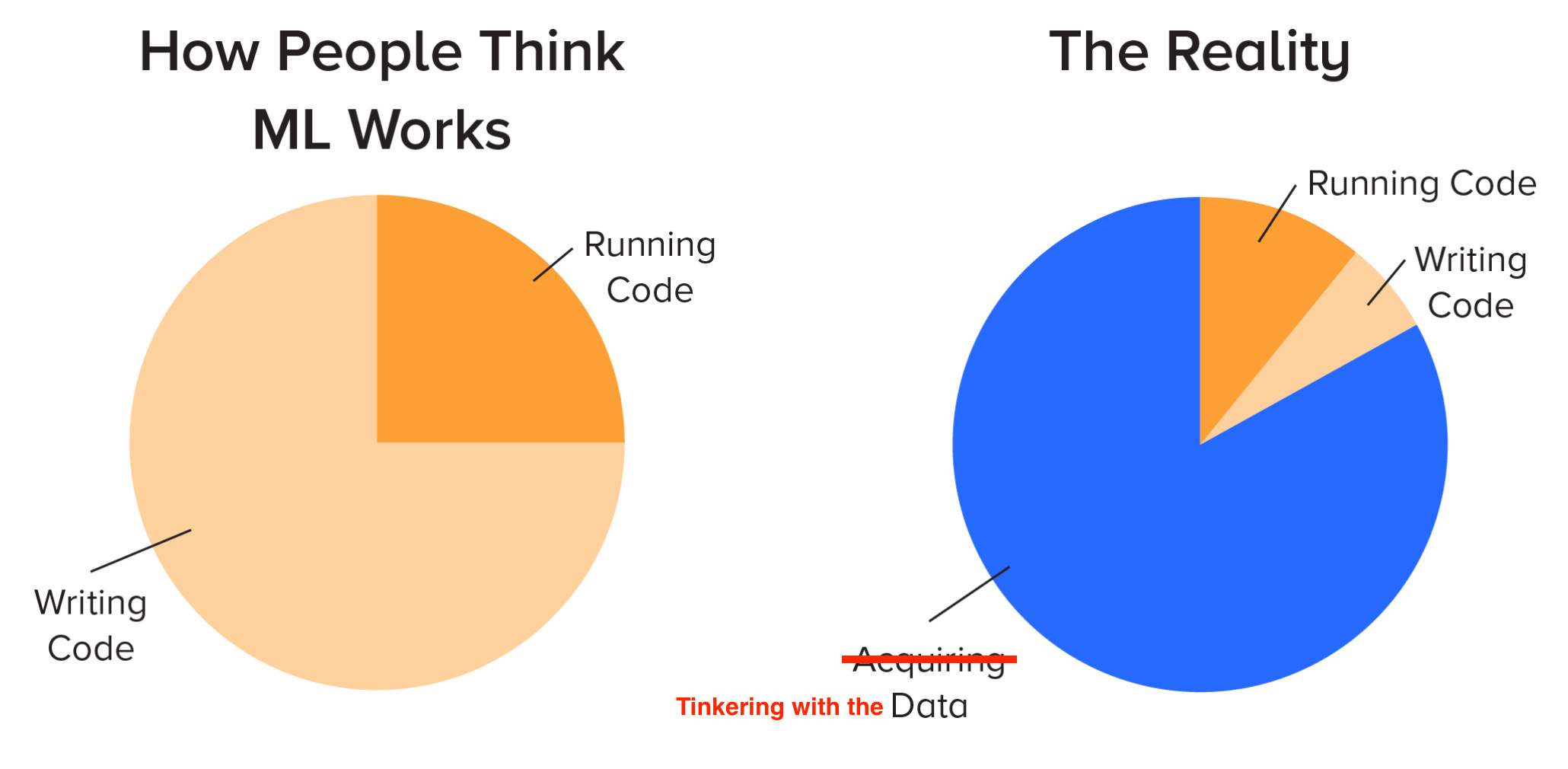
When I first started to solve Machine Learning problems on Kaggle, I thought I would be spending most time tinkering with neural networks and the actual architecture of the model (you know, the “cool stuff”).
In turns out that I’m definitely tinkering, but not with the model. Instead, to improve the competition score, I’m spending most time exploring the data, cleaning it up and inventing features to feed into the model.
More on this
💾 Source code. I updated the notebook from last week to include these feature engineering tweaks.
⚙️ A fancy name for this type of “tinkering with data” is “feature engineering”. Coursera and Google Cloud have a course about it.
In other news
✨ Meta announced it’s putting it’s LLM-based assistant (Meta AI) everywhere across WhatsApp, Instagram, Messenger and Facebook. It supports image generation and (at least for now) is free to use. Not available in Europe yet.
🤖 While at it, Meta also unveiled their latest underlying model, Llama 3. It seems to have impressive performance (enthusiastic disbelief on Reddit), and like the previous Llama models, it’s available for free to use and self-host.
🃏 Joker dancing , made possible by Viggle AI
Postcard from Skopje

I took a few days off to travel around the Southern Balkans. I now made it to Sofia 🇧🇬, where I’m supposed to run a trail run on Sunday morning, but I’m not feeling great. Should I stay put and rest, or should go for it anyway? (Simon Sinek’s voice in my head: this is what we signed up for. We go.)
Have a great week 💫,
– Przemek