
Space Invaders: Teaching a neural network to recognize street art
👾 Invader makes mosaics, we try to teach a neural network to recognize them. How many examples does it take?

Invader makes mosaics.

Specifically, Invader (identity unknown, he always appears in photos wearing masks) creates pixel art mosaics referencing the 1978 arcade game Space Invaders, and sticks them on walls. His works (4000 mosaics and counting!) can be found everywhere around Paris and in over 100 other places on 5 continents.
FlashInvaders
In addition to the physical mosaics, Invader created an associated smartphone app called FlashInvaders, which became an engine of his growing popularity and recognition.

The app gamifies the quest of finding Invader artwork. You get points for each new mosaic you find. The app verifies each catch by visually checking a photo of the mosaic and the GPS location from the phone.
FlashInvaders has built up a cult following over the years. Today you cannot walk for 1 hour in central Paris without noticing someone taking a photo of a space invader. Sceptics say that it’s a silly hobby and there is no point in collecting those points. The collectors respond philosophically by asking what’s the point of anything else that we do in life.
So many artists
Every beginner collector of Space Invaders faces the problem of recognizing which of the many types of street art in Paris is the real Invader artwork. For this week experiment, let’s see if we could train a neural network to recognize the specific art style of Invader and distinguish it from other types of street art!

Fine-tuning a neural network
I built a little training data set by hand, including 28 examples of Space Invaders and 28 examples of other “non-invader” street art. It looks like this (here a sample of 6 photos):

Wait, can you really train a neural network on a data set this small? Just 56 examples? I thought it takes massive amount of compute power and huge data sets to train neural networks?
The key insight for us is that we do not need to train a neural network from scratch. It’s much easier, faster and cheaper to take an open, freely available, already trained base model, and fine-tune it for the specific job.
In our case, I took an existing model trained for recognizing images (resnet18). In training, this model already saw millions of photos. Fine-tuning means just showing it a few images more (in this case, 56 images more), labeled as “invader” or “not invader” and asking the model to learn the difference.
Results
The results of this tiny experiment are promising. The fine-tuned model gets it right for all test images I picked (3 of them below). The test images of course were not part of the training data set: the model didn’t see them before.

Next steps: rather than classifying the artwork as invader/not invader, teach it to recognize the different street artists styles? Also, make it into an app one can download and use on the phone 🤳.
Postcard from Barbizon
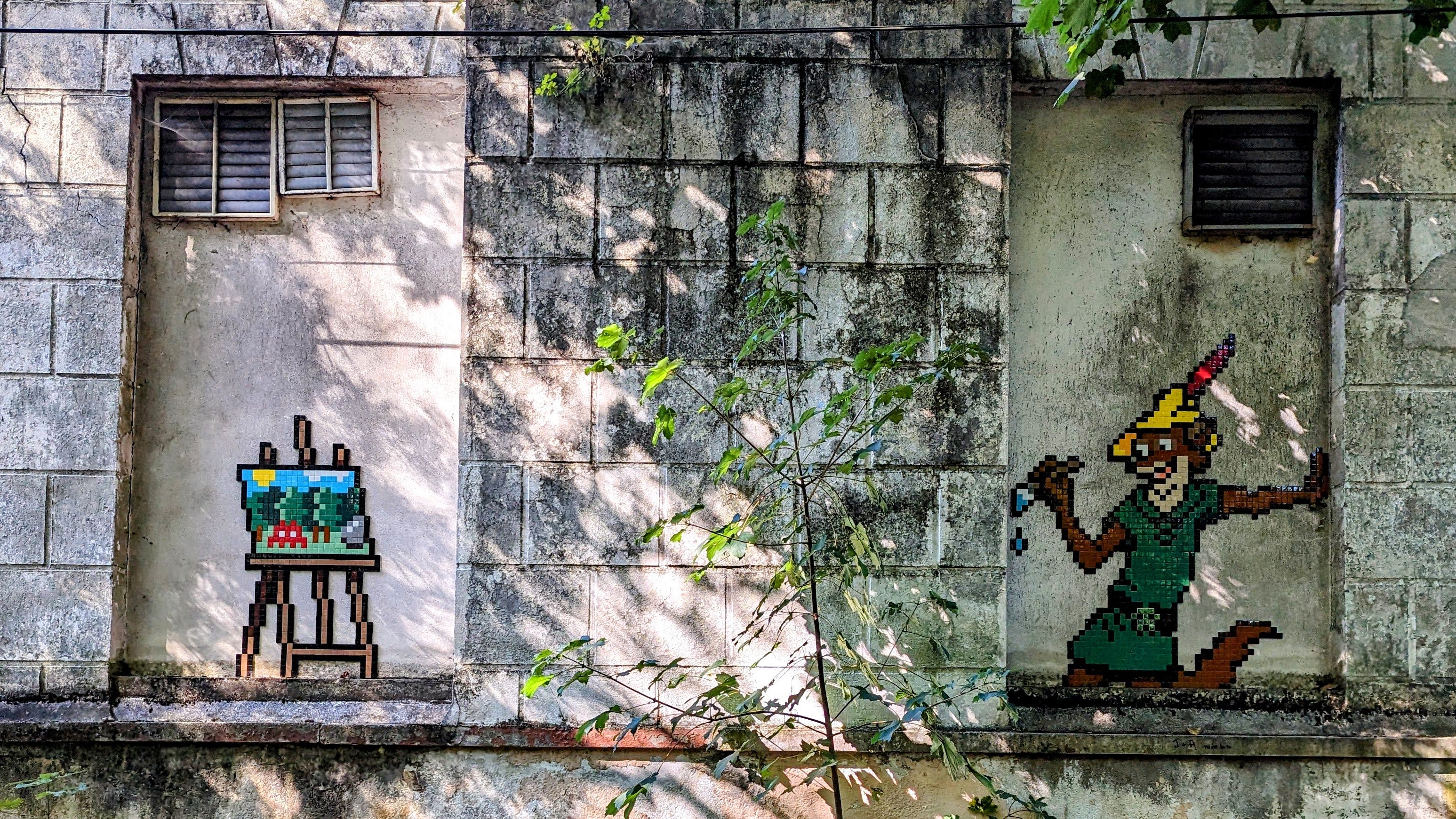
Barbizon, a small town 1h away from Paris has it’s own charming Space Invader artwork 🎨.
I’m finishing this post on Friday, about to take a long bus ride for the trip I mentioned last week. Hope to have a postcard from 🇺🇦 Kyiv for the next time !
Have a great week 💫,
– Przemek