

Link drop is all you need: a Parisian masterclass in minimalism
Link drop is all you need: a Parisian masterclass in minimalism
No flash AI launches made in Paris; closed and open language models; a little test run of Mistral 7B

If we had Oscars for AI launches, the prize for the most minimalist launch would go to Mistral AI.
In the industry that loves flashy demos and presentations, the Paris-based startup announces their language models by dropping a single download link on Twitter:
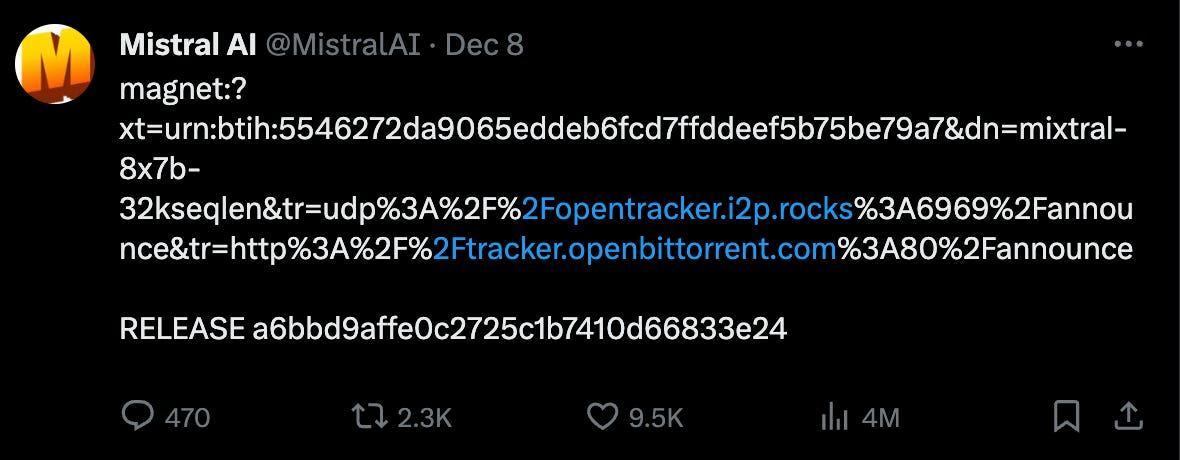
“What is this? Is it modern?” Let’s take a look!
Closed and open AI
Large language models, like those powering ChatGPT, take a long time and a lot of costly compute power to train. Once the model is ready, it can be released in one of two ways.
Closed models are made available to the public without releasing the model itself. The authors may publish a description of the general architecture, but the neural network needed to run the model is kept secret. Anyone who wants to actually use the model, needs to do it via a paid API. The model never leaves the computers of the institution that created it. Examples include GPT-3.5 and GPT-4 from OpenAI (the names can be misleading), Claude 2.0 from Anthropic and PaLM-2 and Gemini from Google.

Open models, on the other hand, are made public in their entirety. The authors release the parameters of the big neural network which powers the model, allowing anyone (with sufficiently powerful computer) to run the model locally, learn from how it’s made and (if the license permits), modify and improve it. The “open” models include GPT-2 from OpenAI, LLama from Meta and the topic of this post: the Mistral AI models.
The “magnet” URL posted on Twitter is a download link. You can use any Torrent client to download the model. All 14.5 GB of it in case of their first model called Mistral-7B, and 87GB for their latest Mixtral 8x7B 💫.

The launch sequence
You can download the models this way, but you probably shouldn’t.
The models as released by Mistral are in their rawest, high fidelity form. These are very heavy and require powerful computers to run. After a model is released, the open source AI community processes them into more digestible versions. In the process, the models are becoming a little less performant, but much smaller and cheaper to run. Think of them like JPEGs and the original model files as RAW images.
The process of compressing the models is called “quantization”. Here you can see TheBloke publishing quantized versions of Mistral 7B. There are many versions depending on the specific technique used, but all of them are significantly smaller than the 14.5 GB original:

Try this at home
If you have a Mac, LM Studio is a very neat tool for running large language models. It hides all of the details we discussed in the previous section and presents a sleek interface with human-understandable hints.
For example, it makes it easier to choose which of the compressed versions of the model we want to run:
the cryptic name Q4_K_S is helpfully annotated as “Small & Fast”
the equally mysterious Q6_K is described as “Less compressed” and “May be slower”

I like fast, and with a single click the model is ready to run:

Testing Mistral 7B
Let’s give it a spin! We’re going to use it to help brainstorm the title for this very post! I’m pasting my first draft into LM Studio with the following prompt: I’m writing a newsletter post about AI and I have the following draft. Can you help me brainstorm ideas for title and subtitle? Please make 3 suggestions.

Example result:
Title: "Mistral AI's Minimalistic Launch: Open Models vs. Closed Models"
Subtitle: "Exploring the Differences Between Releasing AI Models in Their Entirety vs. Keeping Them Secret"
Far from perfect (they never are perfect :)), but they’re close to on-par with GPT-3.5:
Title: "Mistral AI: The Art of Minimalist AI Launches"
Subtitle: "Exploring Mistral's Open Models and the Beauty of AI Simplification"
And here’s the kicker: GPT-3.5 is a 175B parameter model. Mistral 7B is 25x smaller! The fact that I’m getting a capable writing assistant in a model so small that it can run on my laptop is equal parts magical and unsettling.
Worth watching: Mistral AI
I was at Vivatech in Paris this May when the CEO Arthur Mensch joined the French president Emmanuel Macron on stage to discuss the creation of their company. Mistral AI had just raised €105 million at €240 valuation.

The news was met with some scepticism: so much venture capital for a company that didn’t even have a website. Well OK, it had a website ⬇️

6 months later, the company remains decidedly minimalist in their comms. More importantly, by now they released 2 models rivaling the state-of-the-art in their model size classes. Looking forward to what they do next, I’ll have my Torrent client ready 🔥.
In other news
🥊 How are the Mistral models comparing to others? Check out the LLM Arena leaderboard, just keep in mind that the Mistral 7B model is competing there with many models that are much larger. It’s like a boxing fight with an opponent many times heavier.
📰 A technical look at the latest Mistral AI model (Mixtral 8x7b) from
🍿 25 years in Search. This is marketing and it’s designed to make you feel moved and warm. And it works on me every time 🥹
Postcard from Paris

Will Notre Dame reconstruction be finished in time for the Olympic Games next year? Your guess is as good as mine, but the official answer is yes :).
Have a great week 💫,
– Przemek