
We need a better copy-paste for the LLM era
🖼️ The system clipboard contains multitudes

Text is the primary interface of LLMs. Want an article draft checked by a machine? You copy-and-paste it into the chatbot.
The problem is, it doesn't actually work so well! Let's try it on a previous edition of this newsletter:

Select, copy… now we open our preferred chatbot, add a short prompt (Check this section for grammar and other issues) and … paste:
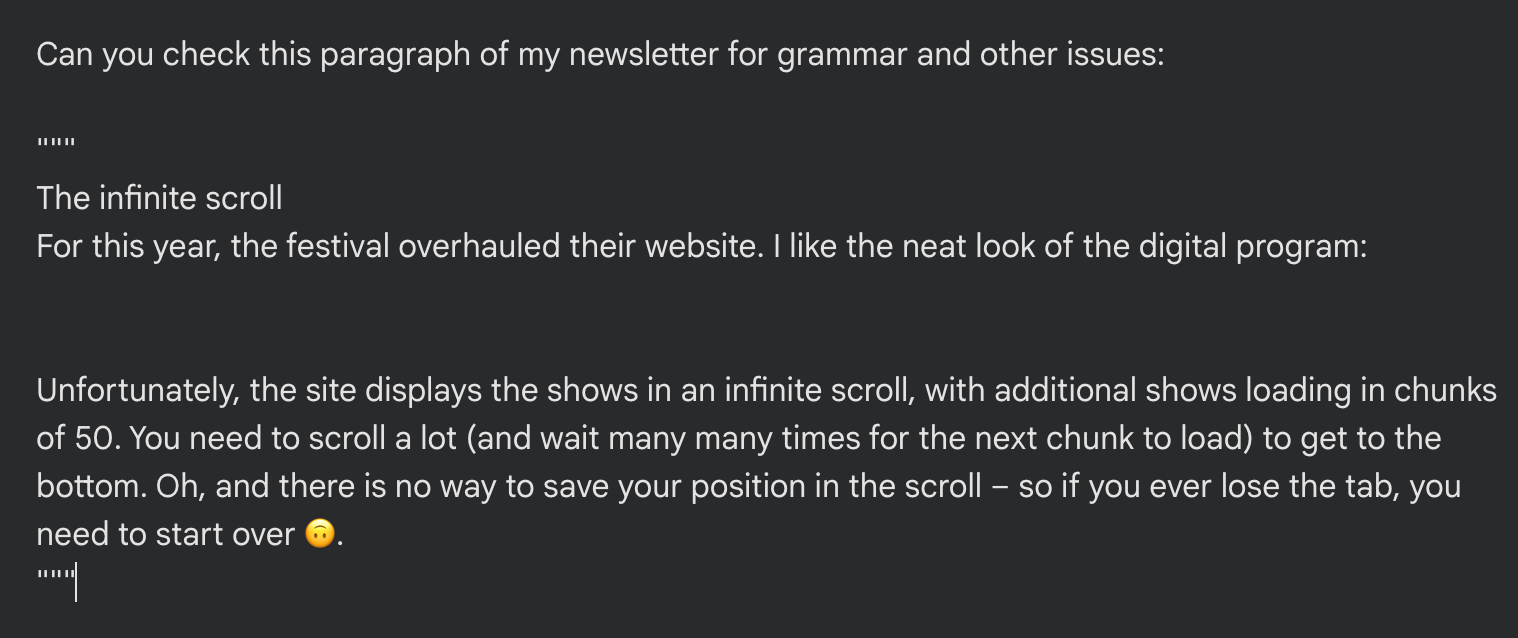
Uhhhh dude where’s my formatting? The section title (“The infinite scroll”) is just in regular plain text. There is no trace of the picture, so the colon at the end of the sentence looks incorrect. The links and the emphasis are gone.
What’s up with that?
The system clipboard contains multitudes
Whenever we copy something from an application like Chrome, what’s stored in the clipboard is not just one piece of data. It’s actually multiple variants of that data in different formats.
For example, Chrome stores the copied web content in multiple formats, including these three:
public.utf8-plain-text
public.html
org.chromium.source-url
public.utf8-plain-text is the plain text version of what we copied. Because the textbox area of the chatbot only supports plaintext input, this is what gets pasted into ChatGPT when we hit Ctrl-V / Cmd-V.
But there’s also the public.html format; that one stores what we copied in verbose original HTML. Thanks to this format, we can paste what we copied into, for example, Google Docs, and the formatting is preserved.
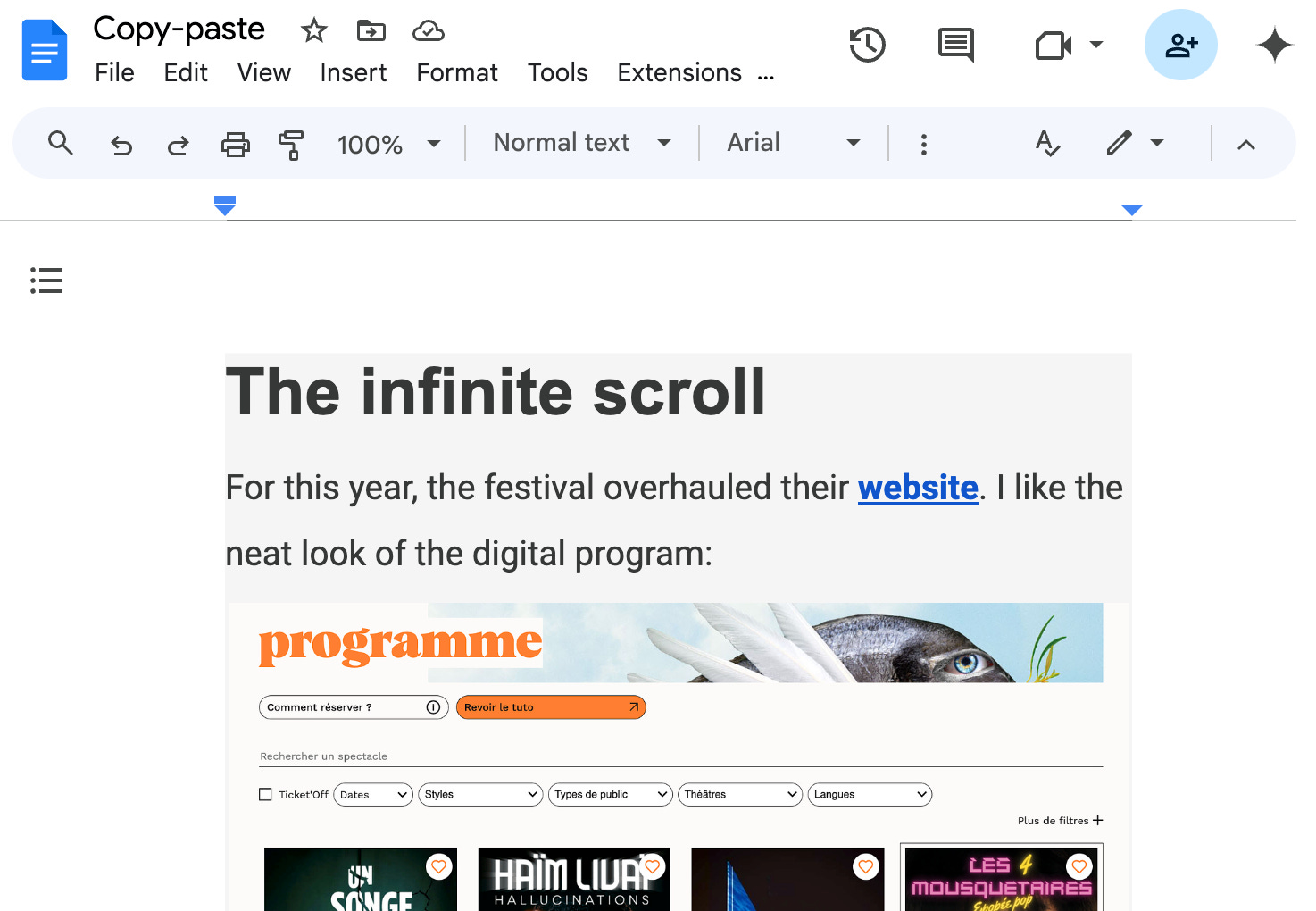
As a little bonus, the org.chromium.source-url format doesn’t actually store the copied content. It stores the source URL from which we copied the content. This enables apps to implement features like this “Pasted from” annotation that appears automagically whenever we paste something (screenshot source):

Better copy paste
OK, now that we know about the multiple formats of the copied web content, we can come back to the problem at hand. How to preserve the semantic information about the text we’d like the LLM to review?
Given that the clipboard stores the html version of what we copied, all we need to do is to convert it to plaintext in a way that converts rich formatting into simplified ASCII characters, rather than discarding it.
clipboard2markdown is a tiny free web tool that does one thing and it does it well: it converts the HTML content in the clipboard into Markdown, a plaintext format with support for simple formatting.

We copy the test snippet from Chrome, we paste … and there we go:

The conversion works great! The section title is rendered as title (with a line of dashes underneath), the picture is replaced by its alt-text description, the links and emphasis are preserved.
Conclusion
Now we can finally pass the Markdown snippet for the LLM to review:
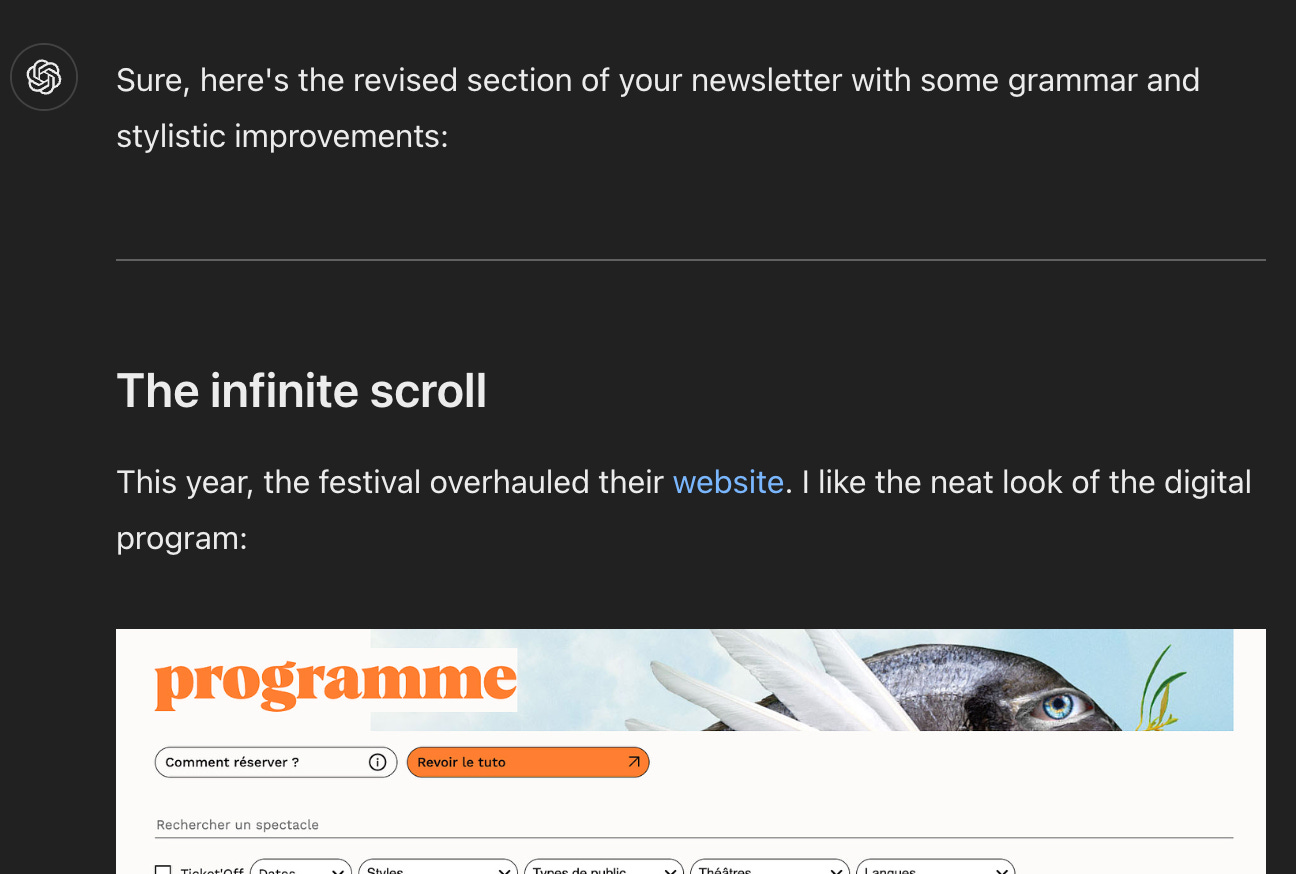
LLMs understand Markdown well so the language review use cases works fine. As a little bonus, ChatGPT renders Markdown output natively, so we get a rich preview of the output.
One day LLM tools like ChatGPT, Gemini and Claude may support rich HTML input directly. Until then, I’m pasting my newsletter drafts in and out of clipboard2markdown 💫.
More on this
🔧 To see how the system clipboard works on a Mac, I used pbv, a handy command line tool to inspect the clipboard content
In other news
📰 A widely commented open letter from Mark Zuckerberg is pitching Meta’s strategy of publicly releasing the weights for their family of LLMs, Llama. The key point is they want to establish Llama as the “industry standard”: As the community grows and more companies develop new services, we can collectively make Llama the industry standard
🤖 At the same time, Meta released their latest Llama 3.1. It may be the first open-weights model that’s competitive against the top tier closed models.
📝 LLMs look like better databases, and they look like search, but, as we’ve seen since, they’re ‘wrong’ enough, and the ‘wrong’ is hard enough to manage, that you can’t just give the user a raw prompt and a raw output - you need to build a lot of dedicated product around that, and even then it’s not clear how useful this is. – Ben Evans
Postcard from Paris

The opening ceremony for the Olympic Games was dazzling and wet. The Parisian streets are eerily empty: it seems that for every visitor who came for the event there are 2 Parisians who left. (I’m staying:))
Here’s to going faster, higher, stronger 💫,
– Przemek